 About us
About us Who We are
Who We are Our Products
Our Products E-books
E-books Contact us
Contact us Skilled Tasker
Skilled Tasker Speedo Delivery
Speedo Delivery Best Match
Best Match Locate Bee
Locate Bee Hire Flutter Developer
Hire Flutter Developer
 Hire Hybrid Developer
Hire Hybrid Developer
 Hire Android Developer
Hire Android Developer
 Hire Frontend Developer
Hire Frontend Developer
 Hire ReactJS Developer
Hire ReactJS Developer
 Hire NodeJS Developer
Hire NodeJS Developer
 Hire Xamarin Developer
Hire Xamarin Developer
 Hire iOS Developer
Hire iOS Developer
 Hire WordPress Developer
Hire WordPress Developer
 Power BI
Power BI
 Power Pages
Power Pages
 Copilot Studio
Copilot Studio
 Power Automation
Power Automation
 Power Apps
Power Apps
 Power Virtual Agents
Power Virtual Agents
 Developer Tools
Developer Tools
 Databases
Databases
 DevOps
DevOps
 Identity
Identity
 Integration
Integration
 Management and Governance
Management and Governance
 Internet of Things
Internet of Things
 Migration
Migration
 Mobile
Mobile
 Security
Security
 Web
Web
 Analytics
Analytics
 Sales
Sales
 Marketing
Marketing
 HR
HR
 Supply Chain Management
Supply Chain Management
 Intelligent Order Management
Intelligent Order Management
 Flutter Development
Flutter Development
 Ionic Development
Ionic Development
 Angular JS
Angular JS
 JavaScript
JavaScript
 Wearable
Wearable
 AR VR
AR VR
 MongoDB
MongoDB
 Amazon Web Services
Amazon Web Services
 MySQL
MySQL
 User Experience
User Experience
 User Interface and Evaluation
User Interface and Evaluation
 User Experience Review
User Experience Review
 Digital Marketing
Digital Marketing
 Social Media Marketing
Social Media Marketing
 PPC
PPC
 SEO
SEO
 IT consultation services
IT consultation services
 Dev Ops
Dev Ops
 Launching and Growth Hacking
Launching and Growth Hacking
 Scope of Work
Scope of Work
 Product Discovery Workshop
Product Discovery Workshop
 Strategic Business Analysis
Strategic Business Analysis
 Food And Beverage
Food And Beverage
 Banking and Financial
Banking and Financial
 Travel and Tourism
Travel and Tourism
 Oil and Gas
Oil and Gas
 Energy and Utility
Energy and Utility
 E-commerce
E-commerce
 Media and Social
Media and Social
 Healthcare
Healthcare
 Hospitality
Hospitality
 Education
Education
 Real Estate
Real Estate
 Customer Support
Customer Support
 Lead Generation
Lead Generation
 Appointment Setter
Appointment Setter
 E-Commerce
E-Commerce

ABOUT Us
our Products
Power Platform
Digital & App Innovation
Supply Chain
Technology
Design
Online Presence
Scaling
Redefining

Ever wondered how banks decide whether to approve a loan or not? It all boils down to credit risk modelling—a crucial tool that helps financial institutions predict if borrowers will repay their loans. Using advanced statistical techniques and machine learning, these models analyze historical data and various factors to forecast the likelihood of loan defaults. Imagine the impact of making more accurate lending decisions, minimizing financial risks, and optimizing lending strategies.
In this blog, we’ll dive into how machine learning enhances this process, improving accuracy and flexibility to navigate regulatory changes, adapt to market shifts, and expand access to credit. Ready to explore how technology is reshaping the future of lending through credit risk modelling using machine learning
Understanding Credit Risk Modeling and its Evolution
What is credit risk modelling ?
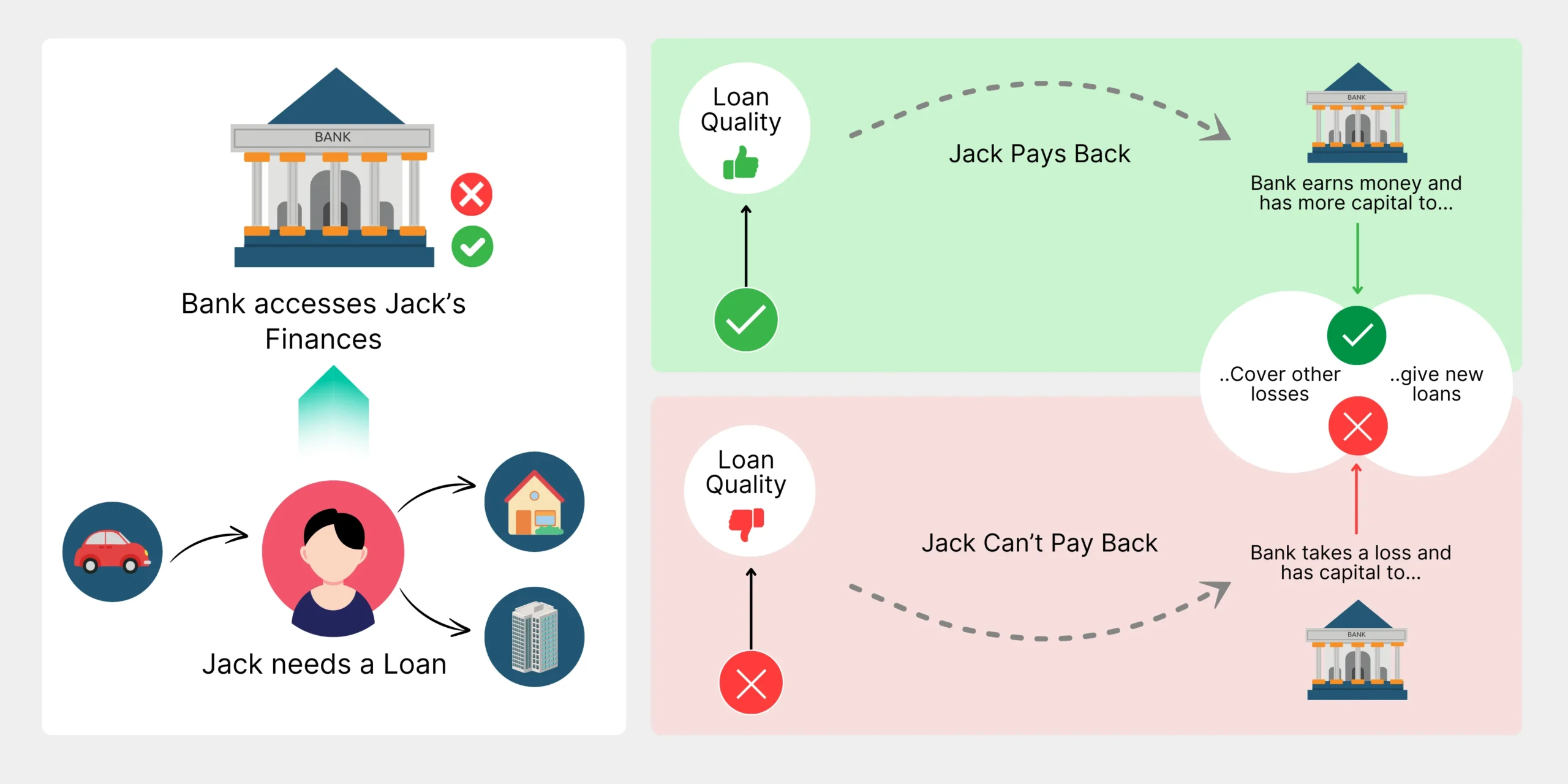
Credit risk modeling is a process used by financial institutions to estimate the likelihood that a borrower will default on their debt obligations in order to make informed lending decisions, set interest rates, and manage overall financial risk. Here are the key components:
Purpose:
Quantifying Default Probability: The primary aim is to quantify the probability that a borrower will fail to meet their debt obligations, allowing lenders to assess the risk associated with extending credit.
Informed Decision-Making: It helps lenders make informed decisions about whom to lend to, under what terms, and at what interest rates.
Methods:
Financial Statement Analysis: Examining a borrower’s financial statements, such as income statements and balance sheets, to assess their creditworthiness.
Default Probability Models: Using historical data and relevant factors to estimate the likelihood of default.
Machine Learning Techniques: Leveraging advanced algorithms, such as decision trees and neural networks, to capture complex relationships and improve predictive accuracy.
Historical Perspective
In the past, credit risk modeling primarily relied on traditional statistical approaches. These foundational methods have paved the way for the more sophisticated models used today.
Logistic Regression
- Purpose:
Logistic regression is commonly utilized for binary classification tasks, such as predicting whether a borrower will default (1) or not default (0).
- How It Works:
This method estimates the probability of an event (e.g., default) based on input features.
- Limitations:
It assumes linear relationships between predictors and outcomes, which can be a significant limitation when dealing with complex credit risk factors.
Linear Discriminant Analysis (LDA)
- Purpose:
LDA seeks to find a linear combination of features that best separates different credit risk classes.
- Application:
It is used for both dimensionality reduction and classification.
- Limitations:
Like logistic regression, LDA assumes linear relationships and the normality of predictors within each class, assumptions that may not always hold true in real-world data.
Transition to Advanced ML Techniques
The financial industry has seen a significant shift from these traditional methods to machine learning (ML)-driven credit risk modelling. This transition is crucial for several reasons:
Increased Accuracy:
- Complex Relationships:
ML models can capture intricate patterns and non-linear dependencies in data that traditional models might miss.
- Adaptability:
ML models can adapt to changing patterns in credit data, leading to more accurate risk assessments over time.
Handling Large and Complex Datasets:
- Big Data:
Traditional methods struggle with the sheer volume and complexity of modern datasets, which can include diverse sources like transaction histories, social media activity, and more.
- Efficiency:
ML algorithms are designed to efficiently process and analyze large, complex datasets, extracting valuable insights that inform credit risk assessments.
Improved Predictive Power:
- Advanced Algorithms:
Techniques such as decision trees, random forests, and neural networks provide superior predictive performance by modeling complex, non-linear relationships in the data.
- Deep Learning:
Deep learning architectures excel at capturing subtle patterns in large datasets, enhancing the predictive power of credit risk models.
Opportunities and Challenges
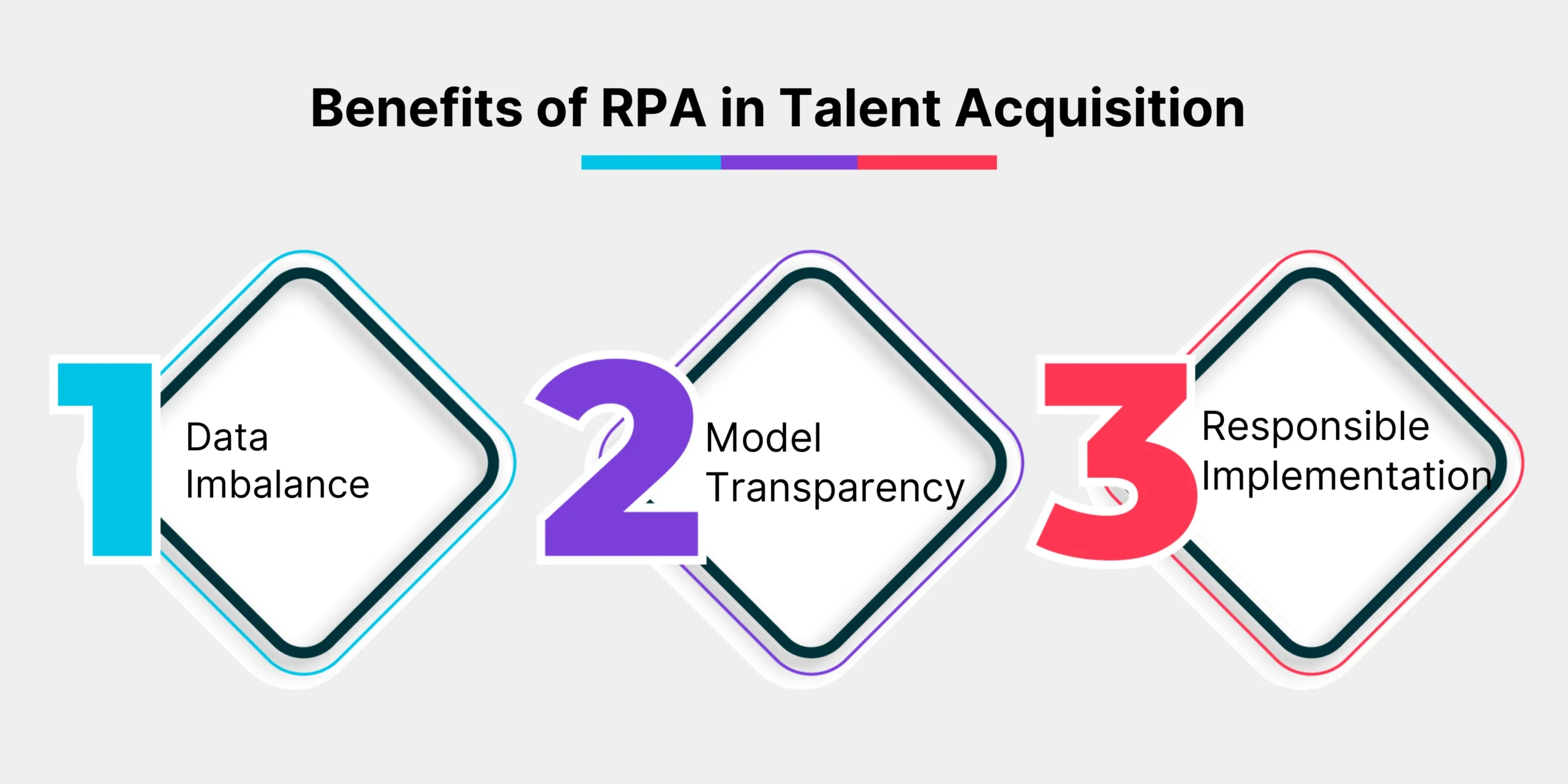
Data Imbalance
Credit datasets often have a significant imbalance between default and non-default cases, skewing model performance. ML models use resampling techniques (e.g., SMOTE) and algorithmic adjustments to handle imbalanced datasets effectively.
Model Transparency
Ensuring ML models are transparent and interpretable is crucial for regulatory compliance and stakeholder trust. Techniques like SHAP values and LIME provide post-hoc explanations for ML predictions, enhancing transparency.
Responsible Implementation
ML models require continuous monitoring and validation to prevent overfitting and bias. Robust model governance frameworks ensure responsible use, providing fair and accurate credit risk assessments.
Common Challenges Faced in Credit Risk Modelling
Data Quality and Availability
- Comprehensive Data Collection:
Obtaining a comprehensive dataset that encompasses all relevant aspects of credit risk can be daunting. Incomplete or missing data can significantly impede accurate modeling.
- Data Cleaning and Preprocessing:
Ensuring data consistency, handling outliers, and imputing missing values are critical preprocessing steps. High-quality data is essential, as poor-quality input will result in poor-quality output.
Model Complexity
- Balancing Complexity and Interpretability:
While sophisticated models like deep learning can capture intricate relationships, they often lack transparency. It is crucial to strike a balance between model complexity and interpretability.
- Feature Selection:
Identifying and incorporating relevant features is a persistent challenge. Irrelevant or redundant features can degrade model performance, making careful feature selection essential.
Handling Imbalanced Data
- Addressing Rare Events:
Credit defaults are relatively rare, leading to imbalanced datasets that can bias model predictions. Techniques such as oversampling (creating synthetic instances of the minority class), undersampling, and SMOTE (Synthetic Minority Over-sampling Technique) are employed to mitigate this issue.
Model Validation and Performance
- Ensuring Robustness and Reliability:
Rigorous validation techniques, such as k-fold cross-validation, are necessary to ensure that the model generalizes well to unseen data.
- Trade-off Between Interpretability and Predictive Power:
Striving for both model interpretability (understanding how the model arrives at decisions) and predictive accuracy is a delicate balance that needs careful consideration.
Explainability in ML Models
- Regulatory Requirements and Transparency:
Regulatory bodies demand transparent models. Explainable AI methods (e.g., SHAP values, LIME) are crucial for interpreting ML model decisions and ensuring regulatory compliance.
- Building Trust:
Financial institutions must justify credit decisions to customers and regulators. Transparent models foster trust and confidence in automated credit risk assessments.
Addressing these challenges requires a comprehensive approach that combines domain expertise, robust methodologies, and ethical considerations.
How Machine Learning Addresses These Challenges?
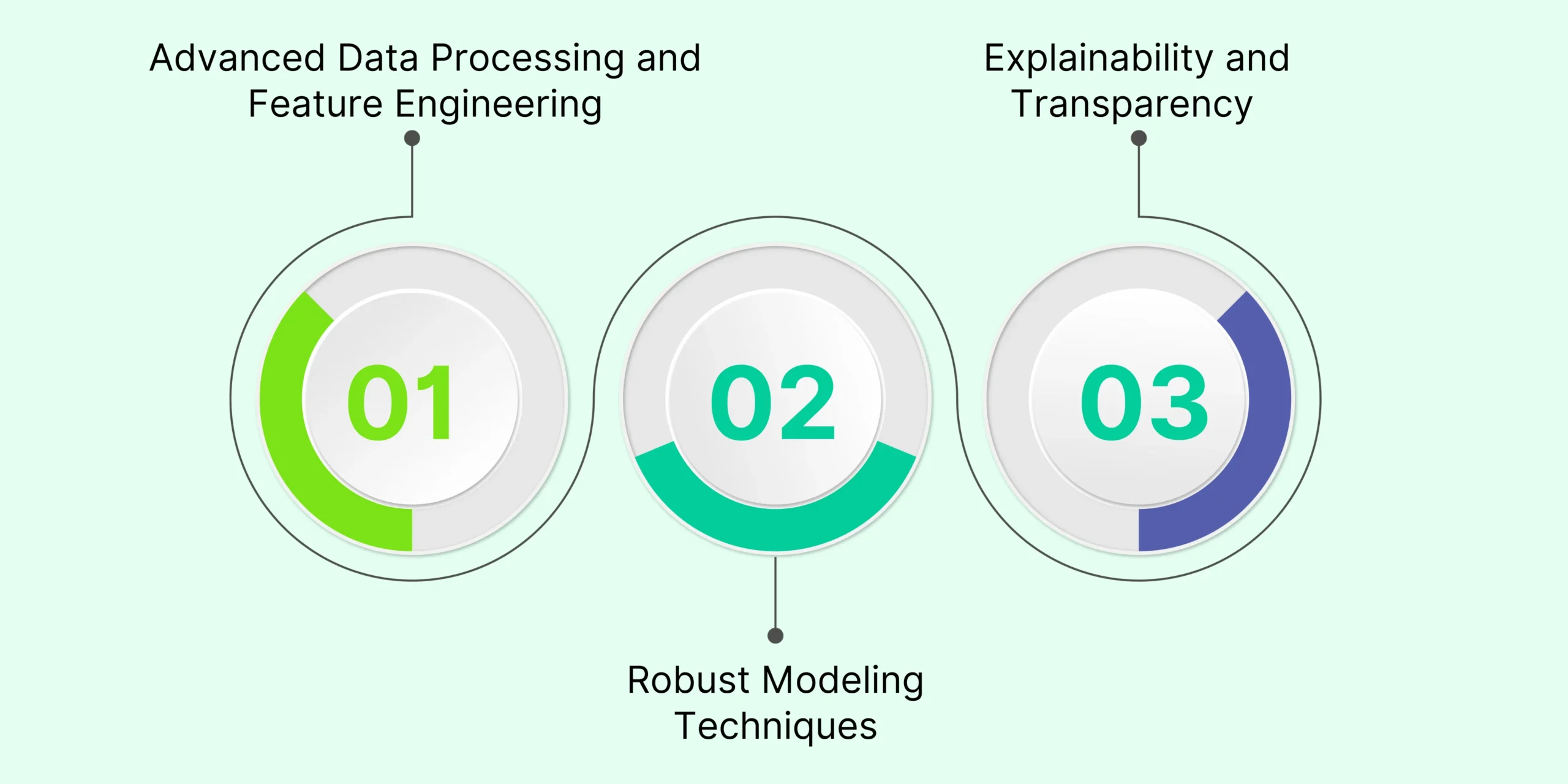
1. Advanced Data Processing and Feature Engineering
Automated Feature Selection: Selecting the most appropriate data from a sizable dataset is a significant task in credit risk machine learning. Machine learning credit risk algorithms can perform this task autonomously. Techniques such as Lasso regression and tree-based approaches like Random Forests help identify and emphasize key features. By eliminating any distortion from irrelevant data, these methods ensure that the credit risk machine learning model utilizes the most predictive data.
Managing Unstructured Data: Conventionally, credit risk analysis models rely on structured data such as earnings, credit history, and employment status. However, unstructured data can provide additional insights. Examples include social media posts and consumer reviews. Natural Language Processing (NLP) techniques can extract valuable information from these sources. For instance, sentiment analysis of customer evaluations can identify signs of financial stress. By integrating unstructured data with structured data, credit risk analysis models improve performance and provide a more comprehensive understanding of credit risk.
Data Augmentation: Credit risk models often struggle with imbalanced data sets where defaults are rare. Data augmentation techniques, such as SMOTE (Synthetic Minority Over-sampling Technique), create synthetic examples of the minority class to balance the dataset. This helps the model recognize patterns associated with defaults, resulting in more accurate and robust predictions. Generative adversarial networks (GANs) can also be used to create realistic synthetic data, enhancing model training.
2. Robust Modeling Techniques
Ensemble Methods: To lower errors and increase accuracy, ensemble methods integrate the predictions of several models. The outputs of numerous decision trees, each trained on a distinct subset of the data, are combined by methods like Random Forests and Gradient Boosting to get a consensus prediction. This method increases the model’s dependability and lowers the chance of overfitting. Ensemble approaches in credit risk modeling capture intricate relationships between characteristics and yield more precise risk evaluations.
Deep Learning Techniques: Deep learning models, especially neural networks, can capture complex and non-linear relationships within the data. In credit risk modeling, deep learning is useful for analyzing a borrower’s payment history over time. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks can model these time-based patterns, providing a better understanding of a borrower’s behavior. This leads to more accurate predictions of future creditworthiness.
Reinforcement Learning: Reinforcement learning algorithms learn optimal strategies by interacting with changing environments. In credit risk, these algorithms can adapt to new market conditions and borrower behaviors. By continuously learning from new data, reinforcement learning models can make better decisions about credit approvals, risk assessments, and loan pricing. This adaptive approach makes credit risk models more robust in a dynamic economic landscape.
3. Explainability and Transparency
Interpretable ML Models: Transparency in credit risk modeling is essential for regulatory compliance and stakeholder confidence. Forecasts are accurate and comprehensible when they are provided using interpretable models, including decision trees and linear regression, which show how each feature influences the final risk estimate. On the other hand, simpler models may not always be as accurate as more complex ones.
Post-Hoc Explanation Techniques: For black-box models like deep learning and ensemble methods, post-hoc explanation techniques help interpret predictions. SHAP (SHapley Additive exPlanations) values and LIME (Local Interpretable Model-agnostic Explanations) are commonly used to explain individual predictions by showing the contribution of each feature. These methods provide transparency by highlighting key factors influencing the model’s decision, making the outcomes more understandable and actionable for credit risk managers and regulators.
Effective Communication: Clear and effective communication of machine learning model outcomes is crucial for building trust with regulators, auditors, and non-technical stakeholders. Visualizations, such as feature importance plots, and detailed reports that explain the model’s decision-making process help demystify complex models. This transparency ensures all stakeholders can confidently rely on the model’s assessments and decisions, fostering a collaborative approach to credit risk management.
By using these advanced data processing techniques, robust modeling methods, and strategies for explainability, machine learning significantly improves the accuracy, reliability, and transparency of credit risk modeling. These approaches together address the limitations of traditional methods, providing a more comprehensive and effective framework for assessing and managing credit risk.



QServices – Editorial Team
Our Articles are a precise collection of research and work done throughout our projects as well as our expert Foresight for the upcoming Changes in the IT Industry. We are a premier software and mobile application development firm, catering specifically to small and medium-sized businesses (SMBs). As a Microsoft Certified company, we offer a suite of services encompassing Software and Mobile Application Development, Microsoft Azure, Dynamics 365 CRM, and Microsoft PowerAutomate. Our team, comprising 90 skilled professionals, is dedicated to driving digital and app innovation, ensuring our clients receive top-tier, tailor-made solutions that align with their unique business needs.

Many enterprise teams treat identity and access as if they are the same thing. They aren’t. Identity confirms who a user is. Access defines what that user is allowed to do. Assuming that an authenticated identity automatically deserves access is one of the most common—and costly organizational security mistakes.

Most enterprises did not choose to be here. Core systems were built to be stable, not adaptable. Over time, layers of customization, integrations, and workarounds turned reliability into rigidity. Today, every new digital initiative feels harder than it should be.

A common industry saying goes, “The cloud does not remove complexity, it moves it.” With Azure IaaS, teams gain the ability to deploy Azure virtual machines, configure networks, and manage storage in a way that closely mirrors on-premise environments. This makes Microsoft Azure IaaS especially attractive for legacy applications, regulated workloads, and hybrid cloud strategies.





Sahil Kataria
Founder and CEO

Amit Kumar
Chief Sales Officer



QServices Inc. undertakes every project with a high degree of professionalism. Their communication style is unmatched and they are always available to resolve issues or just discuss the project.
